



Цена визуального распознавания ИИ
Визуальное распознавание ИИ – это сейчас на слуху, и цена вопроса часто становится первым вопросом, который задают. И тут сразу возникает масса вопросов: сколько это стоит? Что входит в эту стоимость? И насколько реальны обещания эффективности, которые звучат в рекламных буклетах? На мой взгляд, часто наблюдается некоторая неясность в понимании реальных затрат, особенно когда речь заходит о комплексных проектах. Многие пытаются найти универсальный ответ, а он, как правило, не существует. Это как спрашивать 'сколько стоит построить дом?'. Нужно понимать масштаб, функциональность, используемые материалы. В индустрии это понимают, но зачастую запутаться легко.
Факторы, влияющие на стоимость компьютерного зрения
Стоимость разработки и внедрения систем компьютерного зрения — это не просто цена лицензии на программное обеспечение. Это сложная совокупность затрат, и вот основные из них, которые стоит учитывать: Во-первых, это стоимость разработки алгоритмов. Она существенно зависит от сложности задачи, требуемой точности, объема и качества обучающих данных. Во-вторых, стоимость инфраструктуры: необходимо мощное вычислительное оборудование – серверы с GPU, облачные ресурсы. Это может стать весьма значительной статьей расходов, особенно при обработке больших объемов данных в режиме реального времени. В-третьих, это затраты на интеграцию системы с существующими информационными системами предприятия. Например, если вы хотите интегрировать систему распознавания изображений с системой управления складом, то это потребует дополнительных усилий и, соответственно, затрат.
Мы в ООО Чэнду Хуашэнкун Технологической компании (ООО Хуашэнконг Интеллектуальные Технологии) сталкивались с ситуацией, когда клиенты ожидают, что готовое решение 'включи и работай'. На практике это редкость. Чаще всего требуется значительная доработка и настройка, чтобы система соответствовала специфическим потребностям бизнеса. Наши проекты часто начинаются с тщательного анализа требований и определения ключевых показателей эффективности. И только после этого мы можем предоставить реалистичную смету.
Обучение модели и данные
Большая часть времени и, соответственно, средств, уходит на подготовку обучающего датасета. Качество данных напрямую влияет на точность работы ИИ-системы. Иногда приходится собирать и аннотировать сотни тысяч, а то и миллионы изображений. Это трудоемкий и дорогостоящий процесс, особенно если речь идет о специализированных отраслях, где трудно найти готовые датасеты. Например, для системы распознавания дефектов на производственной линии потребуется собрать изображения с различными дефектами, снятые под разными углами и при разном освещении.
Наши клиенты часто недооценивают важность качественных данных. Они думают, что можно использовать какие-то общедоступные датасеты, но это редко дает желаемый результат. В большинстве случаев требуется создать собственный датасет, что увеличивает стоимость проекта.
Выбор платформы и технологий
Существует множество платформ и технологий для реализации визуального распознавания ИИ. Можно использовать готовые облачные сервисы, такие как Google Cloud Vision API, Amazon Rekognition, Microsoft Azure Computer Vision. Это удобно, но может быть дорого при больших объемах данных. Или можно разрабатывать собственные решения на базе библиотек, таких как TensorFlow, PyTorch, OpenCV. Это требует больше времени и ресурсов, но дает больше гибкости и контроля. Выбор платформы и технологий – это компромисс между стоимостью, производительностью и функциональностью. Нельзя выбрать 'самое дешевое', надо понимать долгосрочные затраты, и возможности масштабирования.
Например, мы разрабатывали систему для автоматической идентификации растений на полях. Сначала рассматривали использование облачных сервисов, но выяснилось, что стоимость обработки больших объемов изображений с дронов будет очень высокой. В итоге решили разработать собственную систему на базе TensorFlow, что оказалось более экономичным решением в долгосрочной перспективе. Да, это потребовало дополнительных усилий, но это окупилось.
Примеры из практики: стоимость и результаты
Один из наших клиентов, компания, занимающаяся контролем качества на производстве электроники, хотел внедрить систему для автоматической проверки плат на наличие дефектов. Первоначально они планировали использовать готовый облачный сервис, но результаты оказались неудовлетворительными. Система выдавала много ложных срабатываний и пропускала реальные дефекты. В итоге мы разработали собственную систему, обученную на большом наборе изображений плат с дефектами. Это позволило добиться точности 98%, что значительно превышает показатели облачного сервиса. Стоимость разработки системы составила примерно 500 000 рублей, но в результате клиент получил значительное снижение затрат на контроль качества и повышение производительности.
Ошибки, которые стоит избегать
Часто клиенты совершают ошибки, которые приводят к увеличению стоимости проекта. Например, они не определяют четкие требования к системе или не собирают достаточное количество обучающих данных. Или они пытаются внедрить слишком сложную систему, которая не соответствует их потребностям. Важно начинать с малого и постепенно наращивать функциональность системы. И самое главное – не бояться задавать вопросы и консультироваться с экспертами.
Взгляд в будущее: стоимость искусственного интеллекта в визуальном распознавании
Стоимость компьютерного зрения будет продолжать снижаться по мере развития технологий и увеличения объема доступных данных. Появление новых алгоритмов и более мощного вычислительного оборудования сделает разработку и внедрение систем визуального распознавания ИИ более доступным для широкого круга компаний. Однако, стоимость обучения модели, особенно при работе со специализированными данными, останется значительной статьей расходов.
В ООО Чэнду Хуашэнкун Технологической компании мы постоянно следим за новыми тенденциями в области искусственного интеллекта и компьютерного зрения. Мы предлагаем нашим клиентам решения, которые соответствуют их потребностям и бюджету. Мы не просто продаем технологии, мы помогаем нашим клиентам решать их бизнес-задачи.
Ключевой тренд сейчас – это 'Federated Learning' (федеративное обучение), который позволяет обучать модели на распределенных данных, не передавая их на центральный сервер. Это значительно снижает затраты на хранение и передачу данных, а также повышает конфиденциальность. Мы активно внедряем эту технологию в наши проекты.
ООО Хуашэнконг Интеллектуальные Технологии, основанная в 2011 году, является национальным высокотехнологичным предприятием, специализирующимся на исследованиях, разработках и промышленном применении промышленных роботов и интеллектуальных технологий AI. Компания постоянно стремится создать полную цепочку продуктов, охватывающую интеллектуальные роботы AI. Мы находимся в постоянном поиске новых решений, чтобы помочь нашим клиентам оптимизировать их бизнес-процессы.Соответствующая продукция
Соответствующая продукция




.jpg)
Самые продаваемые продукты
Самые продаваемые продукты-
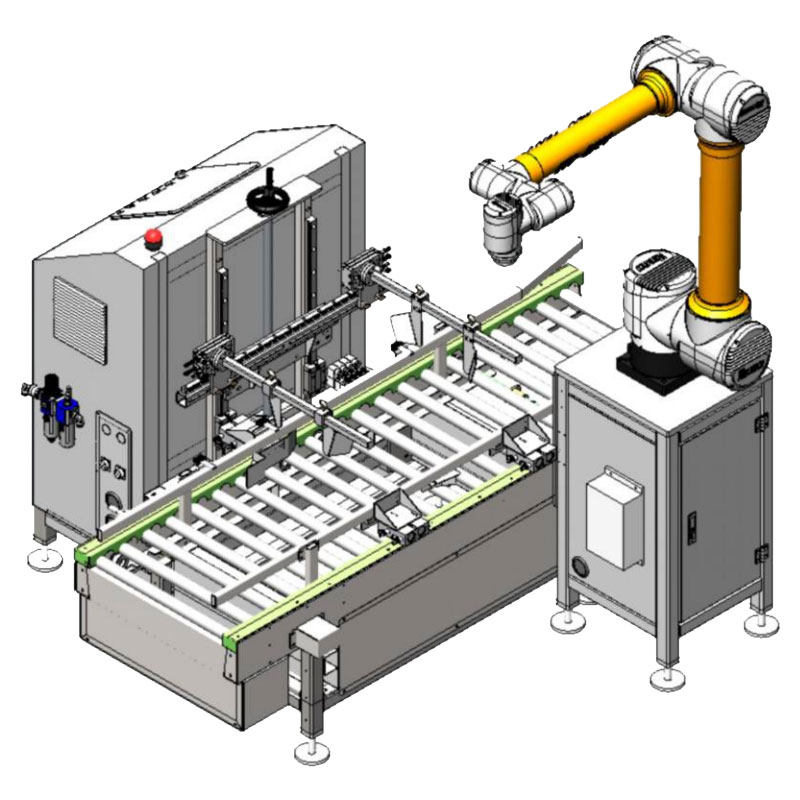 Упаковочная машина для совместной работы серии WSC-ZXX
Упаковочная машина для совместной работы серии WSC-ZXX -
 Чжишэн WSC-800DJ
Чжишэн WSC-800DJ -
 Чжихуа WSC-1000D
Чжихуа WSC-1000D -
 WSC-MD30Max
WSC-MD30Max -
 Универсальная машина для распаковки WSC-KZ-RD60T/-RD60B
Универсальная машина для распаковки WSC-KZ-RD60T/-RD60B -
 WSC-MD25Max
WSC-MD25Max -
 WSC-300E
WSC-300E -
 WSC-MD40PRO
WSC-MD40PRO -
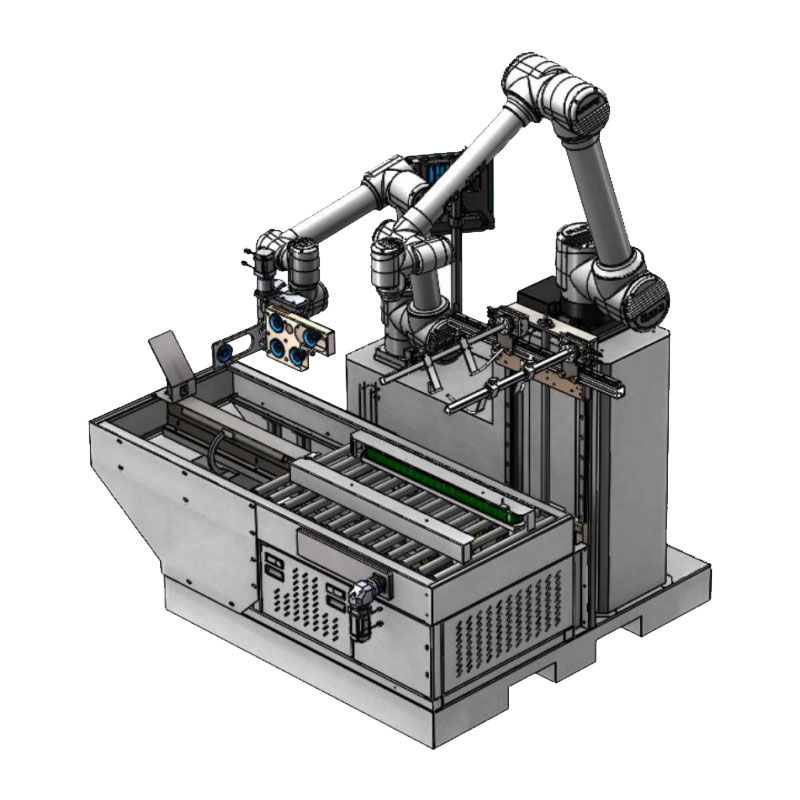 Универсальная коллаборативная машина для вскрытия и установки WSC-KZ-16125
Универсальная коллаборативная машина для вскрытия и установки WSC-KZ-16125 -
 Стандартная машина для упаковки мягких пакетов
Стандартная машина для упаковки мягких пакетов -
 Универсальная машина для вскрытия и запечатывания WSC-KZF-RD60T/-RD60B
Универсальная машина для вскрытия и запечатывания WSC-KZF-RD60T/-RD60B -
 WSC-MD50Max
WSC-MD50Max
Связанный поиск
Связанный поиск- Поставщики высокоточного позиционирования
- Оптовая интеллектуальная сортировка
- Купить робот-захват
- Купить Гибкая автоматизация
- Дешевые датчики камеры
- Установки для автоматизированных сортировочных машин
- Заводы для автоматизированных производственных линий
- Установки для паллетирования продуктов питания и напитков
- Отличная автоматическая термоусадочная упаковочная машина
- Оптовая автоматическая картонирующая машина